
Until now there have been two billing models for running real-time inference: pay-per-token serverless APIs or pay-per-hour dedicated GPUs.
Serverless APIs are an easy starting point. But shared pools mean unpredictable latency and public catalogs limit configuration and control. Dedicated endpoints offer consistent latency and full configuration control, but many applications don't have the sustained around-the-clock utilization to make per-GPU-hour billing work in their favor.
We built Elastic endpoints for the teams caught in the middle. They need the performance of a dedicated endpoint with a pay-as-you-go cost structure that aligns with growth and protects against downside.
The challenge with serverless vs. dedicated server: Custom configuration without consistent traffic
The moment you need a fine-tuned model, custom settings, or have data that needs to be handled in a specific region, serverless APIs stop being a viable infrastructure option. At that point, dedicated servers are the only path forward.
But dedicated endpoints come with a commitment. You're reserving hardware and paying by the GPU-hour regardless of whether your application is handling requests or sitting idle.
The issue is, most user-facing AI products have spiky, cyclical traffic.
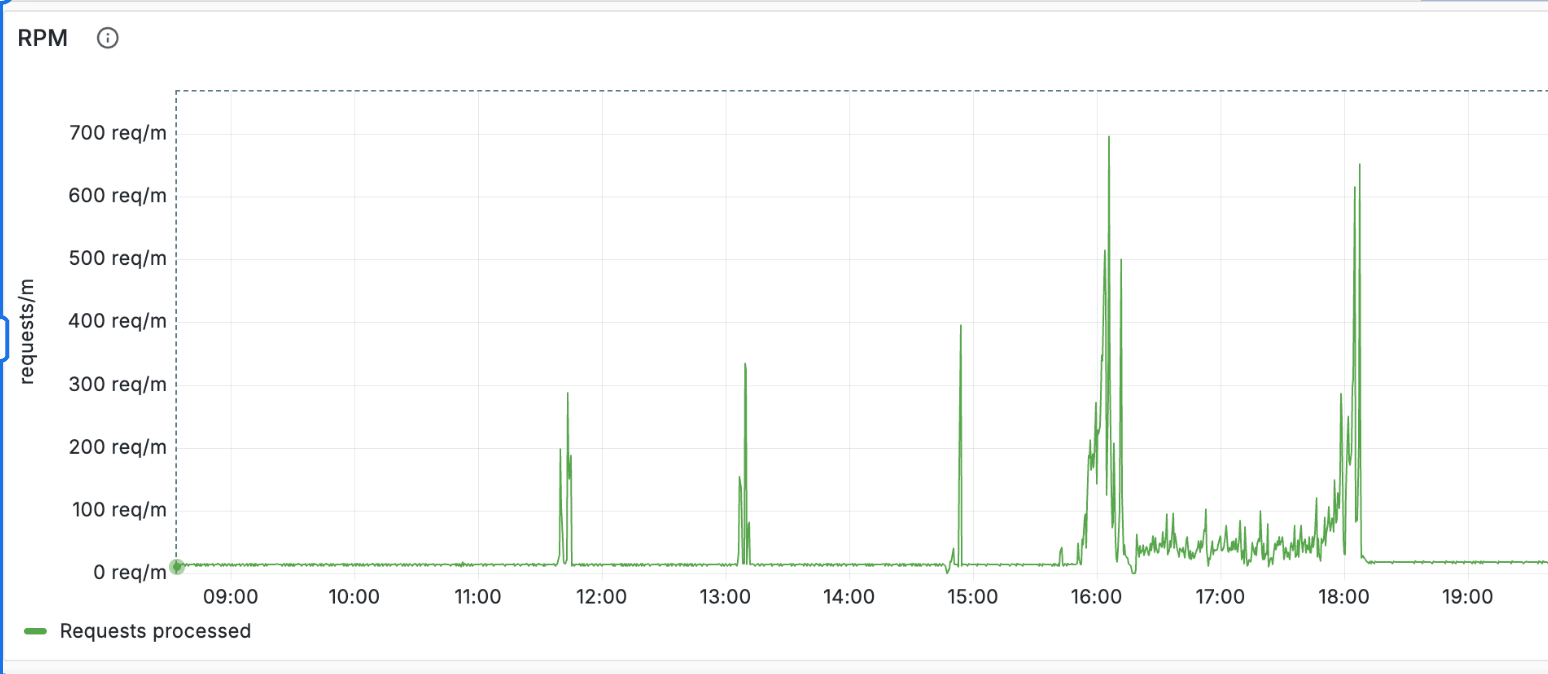
Apps concentrated in one market see requests climb through the day and flatline overnight. Business tools like meeting-note apps and support chatbots peak during working hours and stay quiet over weekends. Consumer and entertainment products are busy on evenings and weekends, but weekday mornings are quiet.
But your dedicated inference bill doesn’t follow this curve.
A GPU running at 10% load costs the same per hour as one running at 100%. At 10% utilization, your effective cost per token is 10x what you'd pay at capacity: $0.013 per thousand tokens becomes $0.13, which is more expensive than premium APIs. (Introl)
For teams still building toward consistent, high-volume traffic, committing to GPU-hour billing is a capital risk that they can’t afford to take.
What are Elastic endpoints?
Elastic endpoints offer per-token billing on private, dedicated hardware.
You rent GPU capacity but get billed only for the tokens you use. No idle-hour charges when the model is sitting quiet. It gives products with spiky inference traffic the two things they need from inference infrastructure: the performance profile of dedicated compute with the cost structure of serverless billing.
How it works under the hood
When you sign up for Elastic endpoints with Parasail, you pay per token instead of per GPU hour and can scale capacity without committing to a specific volume upfront.
What makes this work is where those GPUs go when your traffic drops. Rather than sitting idle, they get allocated to other workloads until your traffic picks back up. When your requests come back in, the capacity is there. When your traffic spikes, autoscaling brings in additional GPUs to absorb the burst.
The piece of engineering that makes this possible is fast model loading. Parasail's engineering team has been working on this for some time, with a series of optimizations covered in our cold-start latency blog series. The closer that swap time gets to zero, the better the GPU utilization across the fleet, and the more sustainable per-token pricing becomes.
How Elastic endpoints compare to serverless, dedicated, and batch inference
Here’s how Elastic endpoints stack up with the other ways to architect your inference: serverless, dedicated, and batch. The best option for your infrastructure depends on a few variables:
- Latency requirements - Are you handling user requests in real-time?
- Traffic patterns - Do you have consistent or spiky usage?
- Pricing - Do you need infrastructure costs to scale with usage or run at a fixed rate?
- Engineering capacity - To what degree are you able to architect your own infrastructure?
How the four inference models compare
Latency, traffic, pricing, and engineering overhead
Latency
Elastic endpoints, from a user’s perspective, are conceptually identical to a dedicated endpoint. The capacity is consistent and the hardware is yours when you need it. When handling synchronous requests, you get the same consistent p95 and p99 latency as a standard dedicated deployment.
That's a meaningful improvement over serverless inference, where your latency depends on what the shared pool is doing at any given moment.
Traffic
Elastic endpoints autoscale, and so do standard dedicated deployments. The difference is what you pay when capacity expands. On a dedicated deployment, spillover is billed by the GPU-hour, whether that extra capacity handles one request or a thousand. On Elastic endpoints, spillover is billed per token. You pay for the burst based on the tokens processed.
They also work as a complement to dedicated deployments, not just an alternative. If you have a reliable traffic baseline but aren't certain how fast you'll grow, you can provision a dedicated deployment for your known capacity and use Elastic endpoints to absorb the 10–50% headroom you'd need if a launch goes well or a new segment takes off. Cost efficiency where utilization is validated, per-token pricing on the capacity you might or might not need.
Pricing
Most serverless providers bundle a retail premium into their per-token pricing to hedge against hardware sitting idle between requests. When you rent a dedicated GPU instance, you assume that idle risk yourself: the meter runs by the GPU-hour whether or not you have traffic.
Elastic endpoints are billed per token like serverless. But because idle GPUs get reallocated to other workloads rather than sitting unused, there's less idle risk to price in. You pay for what you use and don’t have fixed infrastructure costs weighing you down when traffic goes quiet.
Engineering
The biggest advantage of Elastic endpoints for scaling AI teams is the fact that Parasail manages the infrastructure. Unlike standard dedicated deployments, there's no serving framework to configure, no autoscaling rules to write, no MLOps capacity required. Parasail spins up a private endpoint under its own account and extends access. You get dedicated performance while we handle the hosting complexity.
What Elastic endpoints add over serverless is capability. Public serverless platforms won't host a custom model built for one customer. With a private endpoint at a per-token price, teams that couldn't justify always-on GPU costs can now run and evaluate any model without the infrastructure overhead.
Who are Elastic endpoints for?
Parasail’s Elastic endpoints are built for teams running real-time inference, where traffic is not consistent enough to sustain a dedicated GPU around the clock. For products like these, GPU hourly billing is painful even when the latency and model control are worth it.
It’s also a great option for teams that want to deploy a fine-tuned or private model but can't justify the always-on GPU cost at their current utilization. Most companies don't run the math and default to prompting a general-purpose API instead.
Elastic endpoints change the equation: per-token billing on a private endpoint, any model you want, without locking you into capacity or infrastructure that you may not need. For teams billing their own customers per token, the structure aligns cost with revenue.
Elastic endpoints are probably not the right fit if you're just putting a small amount down to test the waters. It's also not the right call for teams with consistent, high-volume 24/7 traffic and no need for managed infrastructure. At that utilization, a traditional dedicated deployment will be cheaper.
Which inference type fits your situation
Build your inference infrastructure with Parasail
Parasail offers Serverless endpoints, Dedicated deployments, Elastic endpoints, and batch inference with flexible infrastructure built to scale with you. Unlike most inference providers, Parasail doesn’t force you into long-term contracts, throttle you at peak demand, or charge a premium for per-token pricing.
If your application has spiky traffic, you want to customize your configuration, or you need a cost structure that minimizes risk, click below to get in touch.
Note: Elastic endpoints are currently in early access, so we'll start with a short conversation to see if it's the right fit.