
At Parasail, we serve inference workloads for our customers hosting hundreds of different models. This number keeps growing as new models are released and we onboard customers with heterogeneous needs.
A common requirement across these deployments is predictable quality of service (QoS), often with strict SLAs/SLOs. However, the first request to a model often incurs high latency: cold-start latency. This is typically driven by three one-time (or cache-miss) steps: (1) downloading artifacts (e.g., from Hugging Face), (2) CUDA compilation, and (3) loading model weights into GPU memory.
Figure 1 shows the startup-latency breakdown to load Qwen/Qwen3-30B-A3B on a H200 GPU with TP=1. Startup latency can be orders of magnitude higher than steady-state end-to-end latency, motivating targeted optimizations. In this three-part series, we describe our approach to reducing cold-start latency to improve customer experience and GPU fleet utilization. We begin with optimizations for loading model weights from disk to GPU memory.

Optimizing model-weight loading from disk
Assuming the model weights are already located on disk (fast NVMe storage device), how do we reduce the time it takes to load to GPU memory? We assume the models are stored in the safetensors [1] format. Before diving into our optimizations, let's look at how a naive safetensors loader works in vLLM to understand the source of inefficiencies.
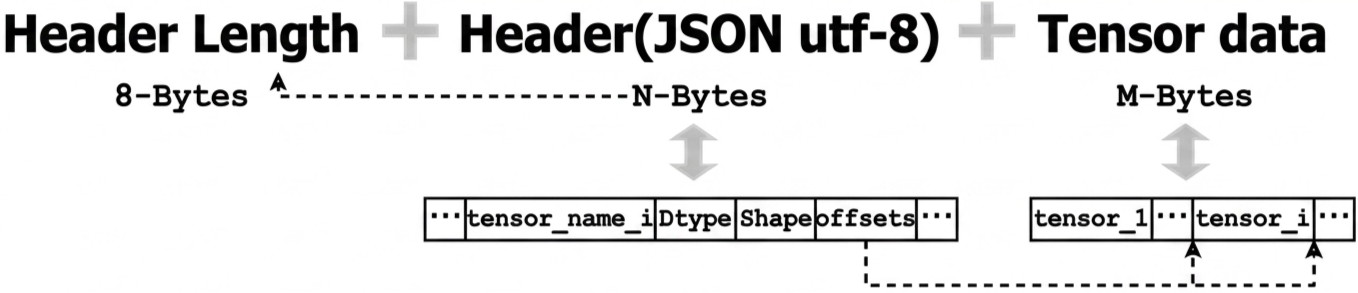
Safetensors format (quick primer)
Safetensors [1] is a zero-copy format for saving models securely on disk. Figure 2 shows the details of the format. The first 8 bytes stores the size of the header (N-bytes). The next N-bytes holds the header which stores metadata about tensors such as the tensor name, data type, shape and their locations (offsets) in the file. The last M-bytes contain the actual tensor data.
How safetensors files are loaded in vLLM today
In vLLM, the header is read first. Then, tensor data is read into host memory and deserialized one tensor at a time in host memory. After getting deserialized, they get copied onto device memory. All of this happens at the tensor level granularity and sequentially through mmap.
Decoupling I/O from deserialization with fastsafetensors
The default loading process can be inefficient because:
- It requires multiple copies (disk → host, host → device).
- It effectively performs small, per-tensor reads/copies because deserialization happens on the host.
Fastsafetensors [2] recognizes this and decouples the I/O path from the deserialization path in their implementation so that each can be optimized individually. Specifically, they read the tensor data as a large buffer directly to GPU memory and perform deserialization of the entire batch in GPU memory. This eliminates the inefficient per-tensor small I/O pattern and enables fast on-device deserialization. Furthermore, this is compatible with GPUDirectStorage (GDS), completely eliminating the host from the I/O path on GDS-enabled machines. We benchmarked this against the baseline and confirmed this brings cold starts down by 3-5x on average across a variety of models with different tensor parallel configurations (Table 1).

Eliminating page-cache overheads with O_DIRECT via instanttensors
On non-GDS compatible machines, fastsafetensors (or any other load format) falls back to the host OS I/O stack. This involves setting up the OS page cache so that further requests are served from there. For large tensors, this can become a large overhead, allocating hundreds of GBs of buffer in the host. It affects concurrency because in-memory buffer allocation can become a bottleneck and serialize the entire workflow. The OS I/O stack, however, allows you to bypass the page cache with the O_DIRECT flag. Figure 3 shows this in the context of the I/O stack. Instanttensors reduces page-cache overhead by using O_DIRECT.
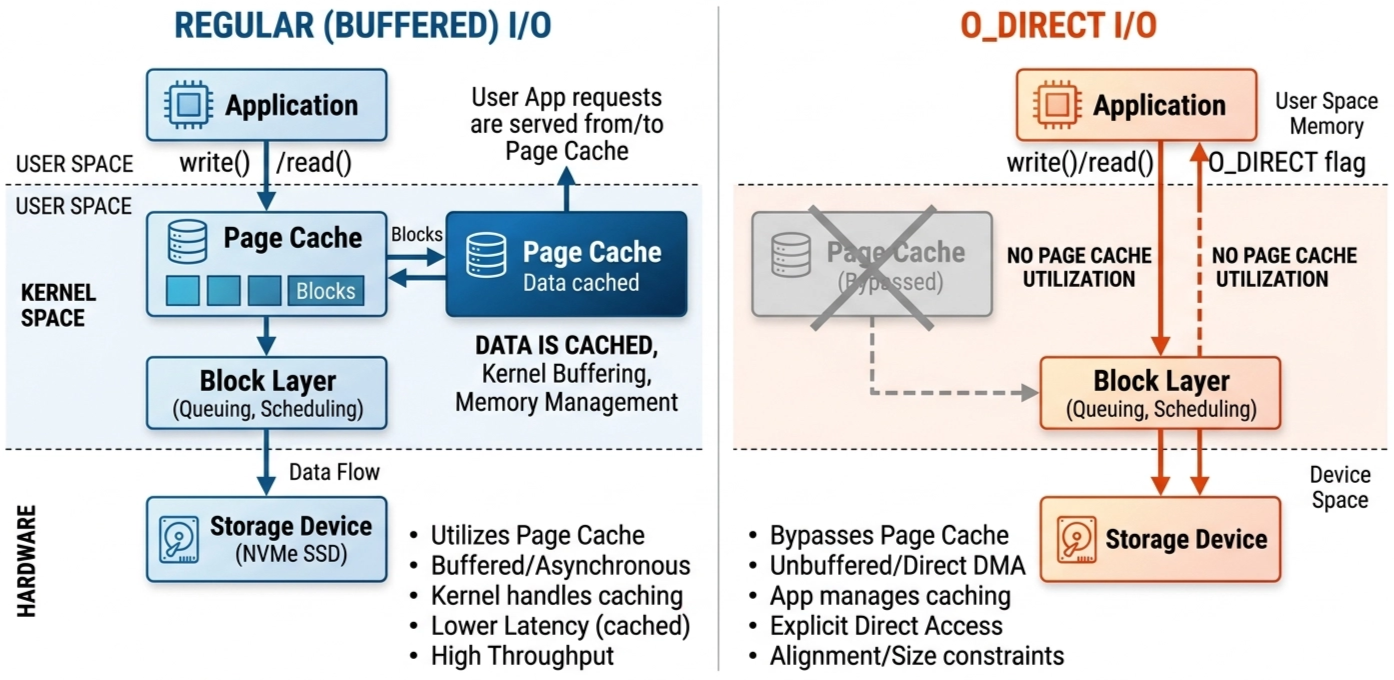
However, warm starts are much slower compared to fastsafetensors or the baseline. This is because requests are always served from disk since we completely bypass the page-cache. We benchmarked this and confirmed the hypothesis. Table 2 shows these results.

Optimization: io_uring for truly asynchronous I/O (fast cold starts AND warm starts)
So far, we see that we are able to achieve good cold-start performance by enabling O_DIRECT. However, this results in higher warm-start latency. Fast warm-starts require trading cold-start performance by paying for the one-time overhead of setting up the page-cache (fastsafetensors). Ideally, we would like a solution that can achieve both fast cold-starts AND fast warm-starts.
Our solution is based on the following observation. In order to achieve fast warm-starts we should read from a cache (the OS manages it for you in a page-cache). At the same time, we don't want the allocation of the page-cache to block I/O progress. What if we could have other threads asynchronously performing different stages of I/O without being blocked on page-cache creation?
Linux kernel version 5.1 introduced io_uring, which lets you do this. io_uring is a Linux-specific API for asynchronous I/O. It allows the caller to submit various I/O requests and processes them asynchronously without blocking the calling process. It uses two circular queues (hence the name "ring") - a submission queue and a completion queue - to track requests and responses. These rings use buffers that are mapped between user and kernel space to avoid redundant copies. Figure 4 presents a high-level overview of the io_uring path. For a more detailed explanation of how io_uring works, see [4].
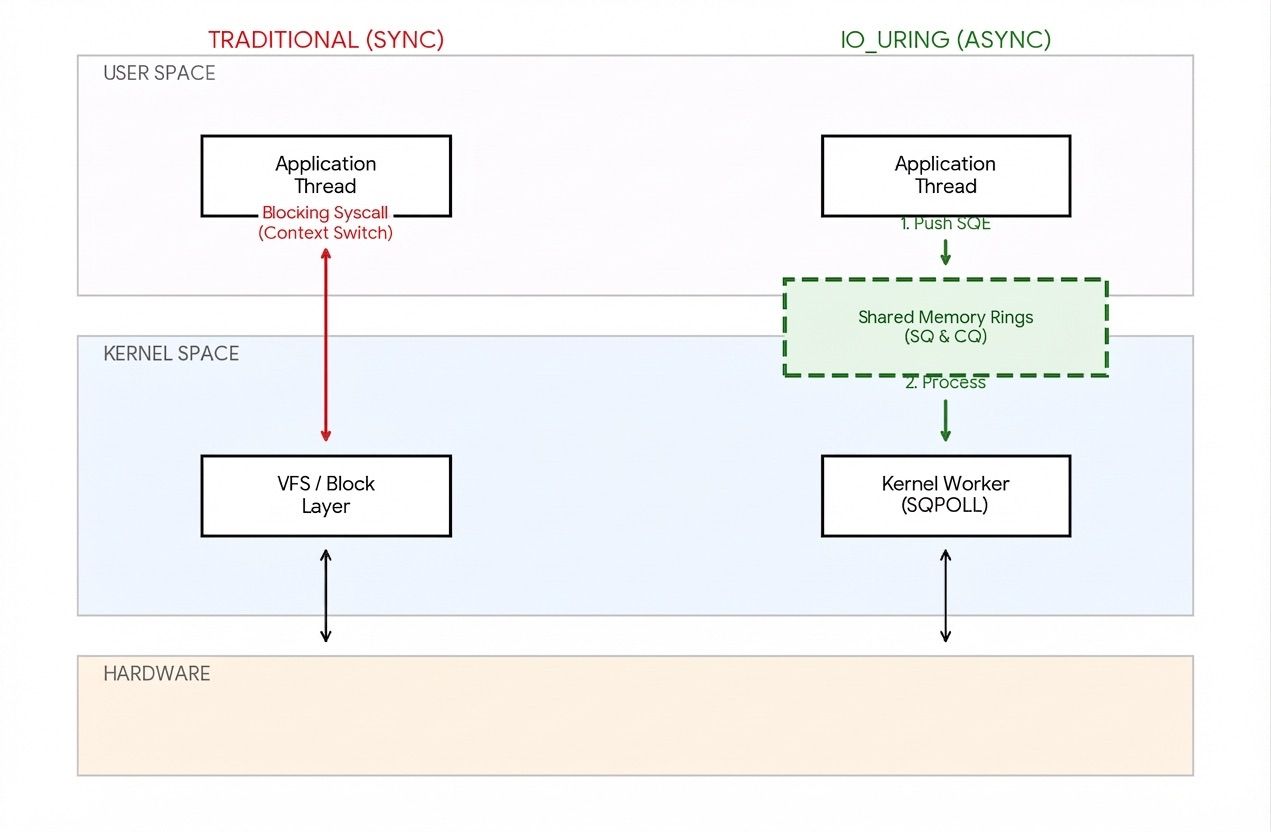
We patched instanttensors to use the io_uring API and observed that warm start latencies are now as fast as fastsafetensors while not degrading fast cold-start latencies. Table 3 shows these results, and the trend is consistent across different sized models and differently sharded models (from TP=1 to TP=8).
Conclusion
We benchmarked off-the-shelf model-loading techniques and found that while each had its strengths, none could achieve low cold-start and warm-start latency simultaneously. Using the io_uring feature to perform truly asynchronous I/O allowed us to achieve low latencies in both cases. Stay tuned for Parts II and III, where we describe optimizations for the remaining stages in model startup.
Acknowledgements
Thank you to fellow Parasail engineers Zifei Tong and Pooya Davoodi for their support in producing this analysis.
References
[1] Hugging Face. (2022). Safetensors [Computer software]. github.com/huggingface/safetensors
[2] Yoshimura, T., Chiba, T., Sethi, M., Waddington, D., & Sundararaman, S. (2025). Speeding up model loading with fastsafetensors. IEEE CLOUD 2025. doi.org/10.48550/arXiv.2505.23072
[3] Scitix. InstantTensor [Computer software]. GitHub. github.com/scitix/InstantTensor
[4] Emelyanov, Pavel. "Database Internals: Working with I/O." ScyllaDB, 25 Nov. 2024. scylladb.com/2024/11/25/database-internals-working-with-io
[5] Google Gemma for the figures.