
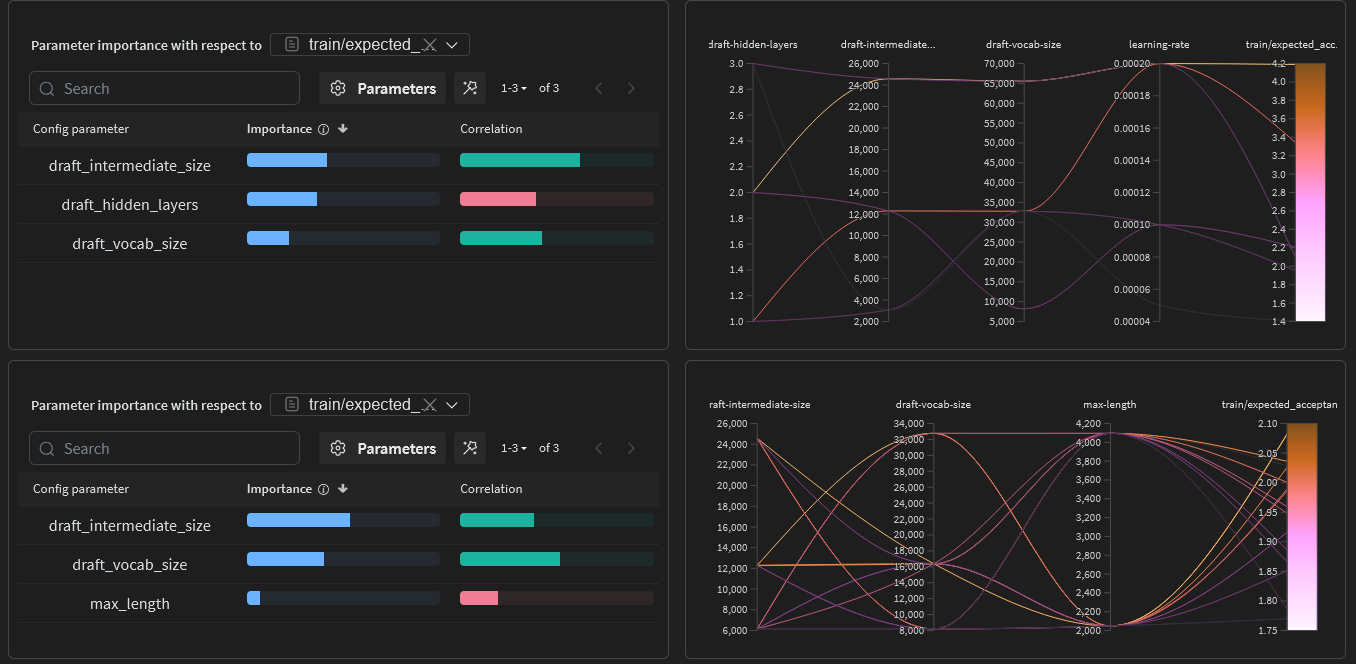
2019 was so long ago that it might as well have been the 19th century. But I still remember reading the GPT-2 paper and being blown away by the "herd of unicorns" example.
For those of you unfamiliar, that was when researchers fed the model with the following prompt: "In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English."
GPT-2 generated a continuation that was eerily coherent, resembling a news-like article about the discovery. Even though it was trained on nothing but text from the internet.
This is when it clicked for me. This was the moment when I realized that language models were not just a toy, but a real tool that could be used for... who knows what. Virtual worlds, interactive stories, game characters - maybe, some day, even code! "Who knows where the technology will be some ten years from now!" I remember thinking.
Heh.
Well, it's been seven years. Not quite the ten I was thinking of, but close enough. And what we see is increased abstraction: rare is the person who can tell the difference between "GPT-5" and "ChatGPT", even though they are very different things.
I suppose it was inevitable. Why dig for gold when you can instead sell shovels? Except it happened fractally. People are now building shovels for their shovels, in an Ouroboros of hole-digging, and now with agent orchestration frameworks, MCP, RAG, knowledge graphs and all the rest, well… the metaphor breaks down somewhat.
The point is that these days, the real value is in the pipelines - and pipelines are only as fast as their slowest stage. An LLM that takes two minutes to summarize a document before passing it to a larger reasoning model? That's your bottleneck. That's where the queue backs up. That's where your customers churn.
At Parasail, that's the problem I've been chewing on: how do we make inference faster without making it more expensive or less reliable? Or worse - inaccurate? I don't want to reach for quantization, pruning, distillation, or other techniques that fundamentally present an inferior version of the model you know and love. It should still be the same model, just faster.
Now, you could rent your own GPUs, spin up vLLM, and call it a day. Honestly, that works fine. Until your model crashes on a Friday evening for inexplicable reasons while you're having dinner with an investor.
But that hints at the solution: We can specialize the model itself so that it's faster for your specific use case.
Which is where Eagle comes in.
A Tool-Assisted Decoding Speedrun
Large language models are called "autoregressive" because of a neat trick: they take in a sequence of tokens, and then predict the next token in the sequence. And then they get that token and plop it on the end of the sequence, and run the whole loop again. Autoregressive. Neat, huh?
This has an obvious downside: they generate one token at a time.
Here's the key insight: during training, you already know the full sequence, so you can check the model's predictions for every position in parallel. It's embarrassingly parallel. But at inference time, you don't know what comes next (that's the whole point) so you're stuck generating one token at a time.
Unless... you had a guess. A bunch of candidate tokens. Then you could use that same training-time trick: feed in the candidates, verify them all at once in a single forward pass, and keep the ones the big model agrees with.
The "generating a bunch of tokens" part is easy - just train a small model. What's more tricky is the "check if they are correct part". But it turns out that if you have a bunch of mostly-sensible tokens, you can use the training-time trick to check the small model's predictions for every position in parallel, in a single pass. That same trick works at inference time - if you already have candidate tokens to verify.
Because that model is small, we can run it multiple times for the cost of running the big model once. And, armed with a bunch of tokens, we pay the cost of running the big model one time and hope that the small model got a bunch of them correct!
So it seems like both parts are the "easy part". What's the catch? Surprisingly, there's none - this trick turns out to work! Speculative decoding is born.
Medusa (and later Hydra) innovate by cutting unnecessary parts of the small model and keeping only the important bits for the task: You don't need your small model to be a full blown language model in its own right - you only need to make it robust enough to guess a few positions ahead.
Eagle improved on this by doing away with the notion of receiving tokens as context altogether. It introduced using the model's own internal representations (the hidden state vectors that exist between layers) as context, and produced a "tree" of possible continuations. Think of it as speculating not just on one future, but on many possible futures at once.
Eagle 2 took this a step further by making the tree dynamic. It had a nifty mechanism of investing more on the branches that were more likely to be correct, but still allowing for the odd branch "just in case", rather than being rigidly locked to a single specific shape. Why waste time predicting tokens you know are going to be discarded?
Eagle 3 worked on the architecture. Instead of capturing a single snapshot of the model's state, it captures the intermediate state at three layers (early, middle, and late layers), which allows it to better capture how the model is "thinking".
With Eagle 3 finally becoming mature and widely adopted by most inference engines, we thought it was time to push our speculative decoding feature further and see what it could do for customers.
Initial tests were mediocre. Most "off-the-shelf" eagle models available for the most popular open source models seemed undertrained - acceptance rates were low, and more often than not, it resulted in a net slowdown. Could we do better?
Hunting Prey
We need a guinea pig, and allenai/Olmo-3.1-32B-Think checked a bunch of interesting boxes.
First, it's a 32B reasoning model: big enough to be useful, small enough to not break the bank. It's exactly the kind of model that our customers would put in the middle of a pipeline to digest documents, extract features or do some preliminary reasoning before handing it off to a bigger model.
Second, it has a hybrid attention architecture. OLMo mixes sliding window attention and full attention layers, which is increasingly common in newer models. If we could make EAGLE-3 work well on a hybrid model, we'd have confidence it generalizes - especially since MoonshotAI keeps dropping sly winks that Kimi K3 is slated to be a hybrid linear-attention model.
Third - and this is the pragmatic one - if we could speed it up, we could squeeze it into a single GPU. The only reason it had been occupying two of them was out of desperation (we wanted to make it faster).
Finally - AllenAI ships open data (for those curious, "Olmo" stands for "Open language models"). Not simply open weights, open datasets, open code! When you're training an Eagle 3 model, you need a large, diverse corpus to generate hidden states from. Having access to high-quality open data meant we could build our training pipeline without begging anyone for a data license.
And Olmo-3.1-32B-Think is a bit of a yapper (AllenAI’s words, not mine!). As a "thinking" model, it was trained to spend a long time inside its CoT. Perfect for speculation!
A quick shoutout to the AllenAI team here. They didn't help us directly with this work, but the open ecosystem they've built made it significantly easier.
There's a subtlety worth calling out. EAGLE-3 works by capturing intermediate hidden states at three points in the model: an early layer, a middle layer, and a late layer. The default heuristic in SpecForge (the training framework I used) just picks three evenly-spaced layers and calls it a day.
That's fine for a standard transformer. But OLMo isn't standard. Its layers alternate between sliding window attention (which only sees a local context window) and full attention (which sees everything). If you blindly pick evenly-spaced layers, you might land on sliding window layers, and your EAGLE head is now learning from representations that are missing global context.
Don't get me wrong, this would work (Eagle 3 is great!), but it's not ideal. So we shifted the target layers to land on full attention layers specifically. This is a small change: a few lines of config and a small patch to the model code. But it matters. The EAGLE head doesn't care which layers you give it, just that they're informative. Full attention layers are more informative.
So that's our model. Now comes the hard (fun?) part: training it.
Some assembly required
Training an EAGLE-3 head is conceptually simple, especially with SpecForge: You pick a model, cobble together some sort of dataset (the default ones are... adequate for experimentation), find some example config that kinda sorta looks like the model you pick, and send it! Out the other end comes a trained EAGLE head. If you're lucky.
We already have the model part sorted out. So next step: pick a dataset. Or, if you're smart, more than one.
Our dataset blend tries to cover the full spectrum of what OLMo-3 can do: multi-turn conversations, multilingual reasoning, code, and tool use. We relied heavily on the Dolci datasets here - the same data that was used to train Olmo itself! - and added a few more to round out the coverage. Special shoutout to allenai/Dolci-Instruct-SFT, which is a very eclectic mix with system prompts and tool use!
The SpecForge guide will tell you this, but it bears repeating: you need to regenerate the final assistant turn using your actual model.
Let me explain. Any dataset you pick will likely be formatted in a manner resembling the OpenAI Chat API format, or be castable to that. It doesn't matter if there are tool invocations in the middle, or if the conversation is a hundred turns long. What matters is that you are going to take the last message of each conversation (assuming it's an "assistant" message) and discard it. And then you're going to ask your target model to generate a new one.
This may take the form of a tool invocation, or a direct response, or a refusal. It may be correct, or it may be wrong. The response might be worse than the original one from the dataset. It does not matter. As long as the model generates some manner of content, you're good! Remember: you're training an EAGLE head to predict what the original model would have output, not to produce a good answer!
So that's exactly what we did: we took the last message of each conversation, discarded it, and asked OLMo-3. This too is highly parallelizable, and can be orchestrated by something as simple as a Raspberry Pi (though we didn’t actually use one. If you do, send pics)! Because the Parasail API supports sending batches of requests, and we already know all the prompts we want to send, we can send them all at once, and let Parasail sort them out. We don't need any big GPUs for this part!
You're going to need a bigger boat
Now that you have your dataset prepared, it seems like you should just be able to rent a few GPUs and tell SpecForge to go to town. You can certainly do exactly that.
See, EAGLE-3 needs to learn from the model's internal representations - specifically, the hidden state vectors at three intermediate layers, for every token in every training sample. So you need to obtain these hidden states somehow. SpecForge offers two approaches to do this:
The first, confusingly named "online" training, involves booting up the main model, and then running your dataset through it. This uses the trick we mentioned early on: instead of running the model "autoregressively", you give it the entire response at once, and capture the hidden states in a single pass. You get massive throughput by doing it this way, so it's a lot faster than you'd think! But there's a way to make it even faster.
The second mode is named "offline" training. It involves doing exactly the same thing as the online mode, but with one critical difference: you don't train the EAGLE model. Instead, you simply save all the intermediate states to disk! This has several advantages:
- No context switching*: The capture phase is only concerned with capturing data. You don't need to capture, switch modes to train the eagle head, compute gradients - none of that. You simply capture the intermediate state, then move on to the next sample.
- Training the EAGLE head is cheap*: Once your data has been captured, you can offload the main model. EAGLE only needs the intermediate states, which now live on your disk. And because the EAGLE model itself is so small, you don't need big GPUs in a huge cluster to train it! This is important to emphasize: Even if your EAGLE model is supposed to be bolted to a multi-trillion parameter behemoth, you can train it on a single GPU!
- Multiple epochs are free*: And you will want multiple epochs. Our training curves showed substantial improvement all the way through epoch 6. With online training, every epoch means another full forward pass through the base model. With offline training, you're just re-reading files from disk.
- Disk bandwidth isn't a bottleneck*. Despite the terrifying total size, which we'll get to, this is sequential reads with minimal random access. 300 MB/s is plenty. Spinning rust will do fine - we used HDDs at ~300 MB/s with no GPU stalls.
Let's talk numbers.
Each training sample stores:
- The token IDs (for practically any modern model, because vocabularies are so large, these are going to be stored as an INT64 array. 8 bytes per token)
- A loss mask (a boolean array, but stored as 8 bytes per element due to a safetensors quirk)
- The hidden states at 4 points: the input embeddings plus the three intermediate layers that EAGLE requires (Each at
hidden_sizex2 bytes, because it's done at bf16 precision)
For OLMo-3.1-32B with a sequence length of 2048 and hidden size of 5120, that comes out to ~80 MiB per sample
Scale that to 500k samples, add ~5% to account for serialization overhead, and you get ~42 TiB total.
Here's the counterintuitive part, but for once it's a positive surprise: this doesn't scale with model parameter count. It scales with hidden_size. A 670B MoE model and a dense 3B model with the same hidden dimension cost the same disk space. A trillion-parameter model with hidden_size=8192 would only be ~1.6x more expensive to store than our 32B model. The number of layers doesn't matter! EAGLE-3 always captures exactly three (plus embeddings), regardless of model depth. And the time it takes to train the eagle model itself is practically constant!
On sweeping generalizations
One thing you'll notice when you start training an EAGLE head is that there are a bunch of things in the example configuration files. Some of them you can't change, some of them you can. But... what's the point? What do the knobs do? What's the right setting? Well, let's find out!
Because we're doing offline training, running sweeps is cheap: Instead of training a single eagle head, we trained a whole bunch, each with a different combination of settings. Here's what we learned:
- Vocabulary size (8k, 16k, 32k, 64k)*: The EAGLE head can be configured to use a smaller vocabulary than the base model, and by default, that's exactly what it does. OLMo's vocabulary consists of ~100k tokens, but EAGLE only needs to predict among the most common tokens. We found high variance across vocab sizes with no clear winner. We recommend sticking to the default of 32K.
- Intermediate dimension (6k, 12k)*: By default, this is a factor of the model's own intermediate dimension (usually 1x), though from looking at examples, some configs will double it and some will halve it. This is the "width" of the EAGLE model's feed-forward layer. It's the only hyperparameter that meaningfully affected performance! Bigger is better, up to the point where the drafter becomes too slow to be worth it. You might want to play with this, but we think the default (same as the model's intermediate dimension) is a good starting point.
- Max context length (2048, 4096)*: Surprisingly, 4096 hurt performance. The default 2048 is fine. Don't push it.
- Number of hidden layers (1, 2, 3): This one's a double gotcha. Adding layers did not meaningfully improve training metrics. And even if it had, SGLang refuses to load an EAGLE model with more than one layer at inference time. So you'd be training a model that underperforms AND that you can't deploy. We learned this the hard way so you don't have to.
- Learning rate*: You can run the eagle training "warm" (~1e-4), which is the default. This isn't very surprising but is listed here for completeness.
Here's the thing: the accuracy of the EAGLE head's predictions is about the only thing that matters. Tweaking the training hyperparameters did not meaningfully budge the accuracy.
We plotted average acceptance length against throughput across all 16 models in our sweep. The result was a near-perfect linear correlation. The models that predicted more tokens correctly were faster.
This sounds obvious in retrospect, but it has a practical implication: stop tuning hyperparameters and focus on your training data. More diverse data, more epochs, better dataset curation - these will move the needle far more than any architectural tweak.Counting your chickens
Our training curves looked incredible. By epoch 7, the per-position accuracy was hovering around 80% across all speculative depths. The theoretical boost metric — our naive estimate of the maximum possible speedup — exceeded 4x. The wandb dashboard was a wall of up-and-to-the-right charts.
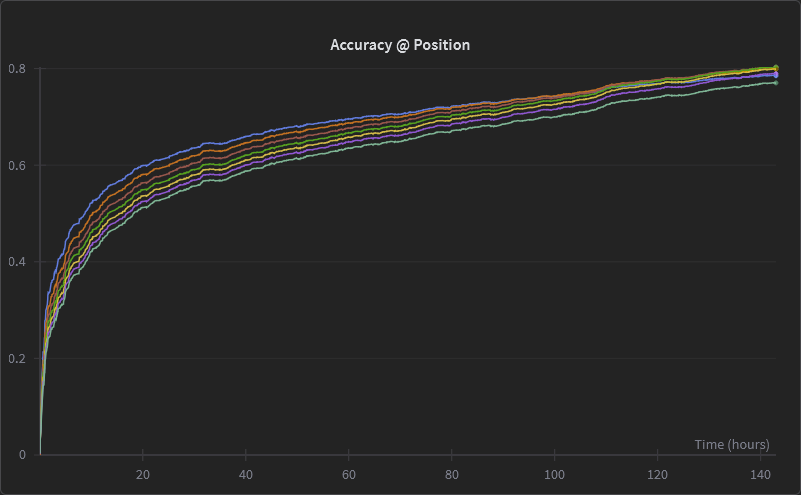
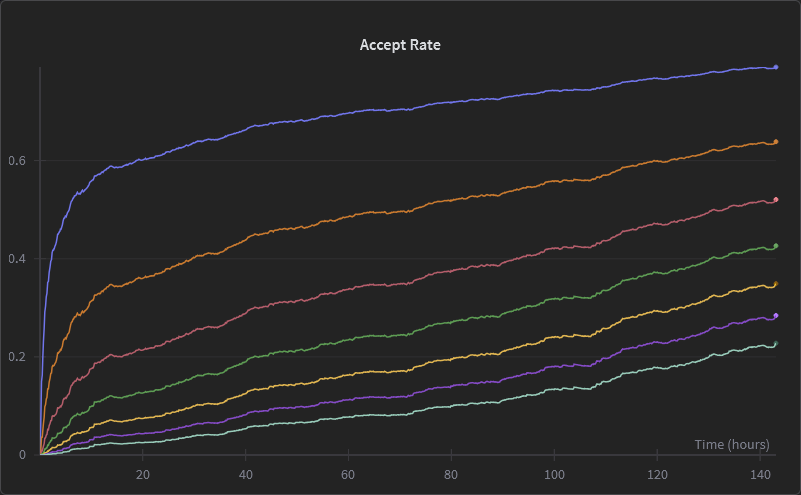
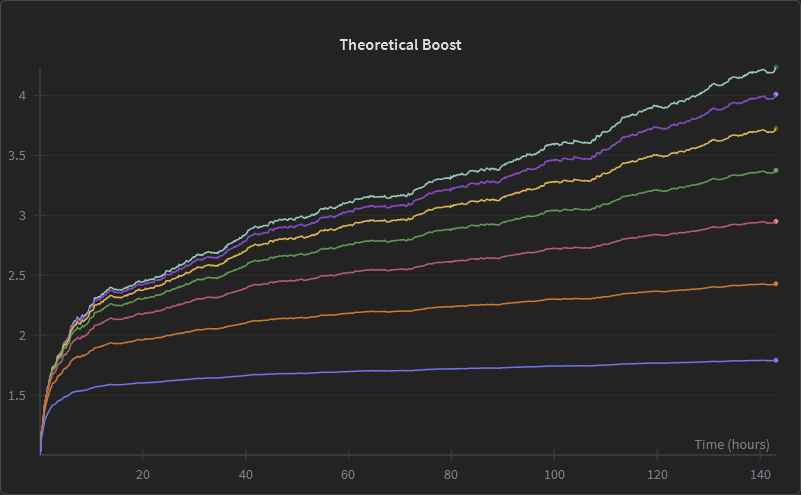
With the training now concluded, we can start our search for the best intermediate checkpoint! So the game now becomes:
- Pick an EAGLE checkpoint and load it in SGLang alongside OLMo
- Run the ensemble through several benchmarks (we chose gsm8k, humaneval and mtbench)
- Compare with the baseline model (No speculative decoding)
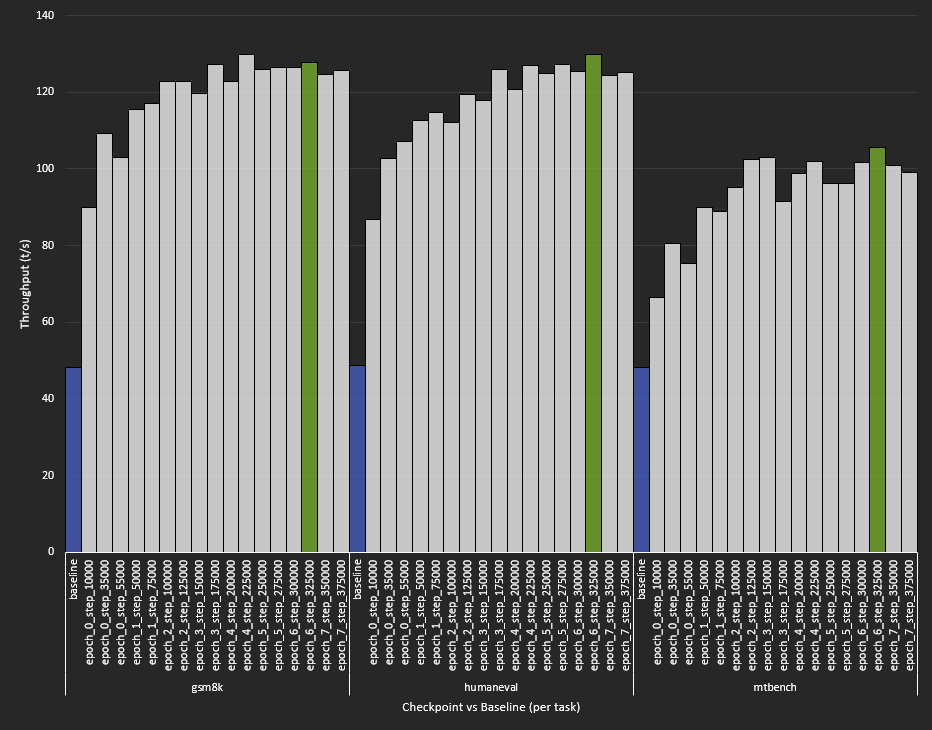
Despite our training charts showing incredible results, here’s the reality check:
- Even a little training helps. Halfway through the first epoch, we already see 1.4~1.9x speedup depending on the task.
- Performance plateaus around epoch 4 for structured tasks like gsm8k and humaneval, and keeps noisily improving for mtbench through about epoch 6.
- After the plateau, training metrics keep improving but benchmark throughput doesn't, and even starts degrading slightly! This is a classic symptom of overfitting: the model memorizes the training distribution instead of learning generalizable patterns.
- Per-task variance is enormous. GSM8K and HumanEval hit ~2.6x speedup. MTBench peaked at ~2.2x. The baseline throughput was identical across tasks (~48 t/s), so the difference is entirely about how predictable the output is.
This last point was very surprising, even though in retrospect, it shouldn't be. Math and code have more repetitive structure. Open-ended chat is, evidently, harder to speculate on.
We selected our final checkpoint - epoch_6_step_325000 - based on the best average performance across all benchmarks, not peak performance on any single one.
The takeaway is that you should be careful about your training metrics. Benchmark your checkpoints on real tasks, on a real engine, with real inference parameters - and even then, expect production data to give you very different results!
A diving eagle beats a soaring one
With our final checkpoint in hand, we swept the inference-time parameters in SGLang:
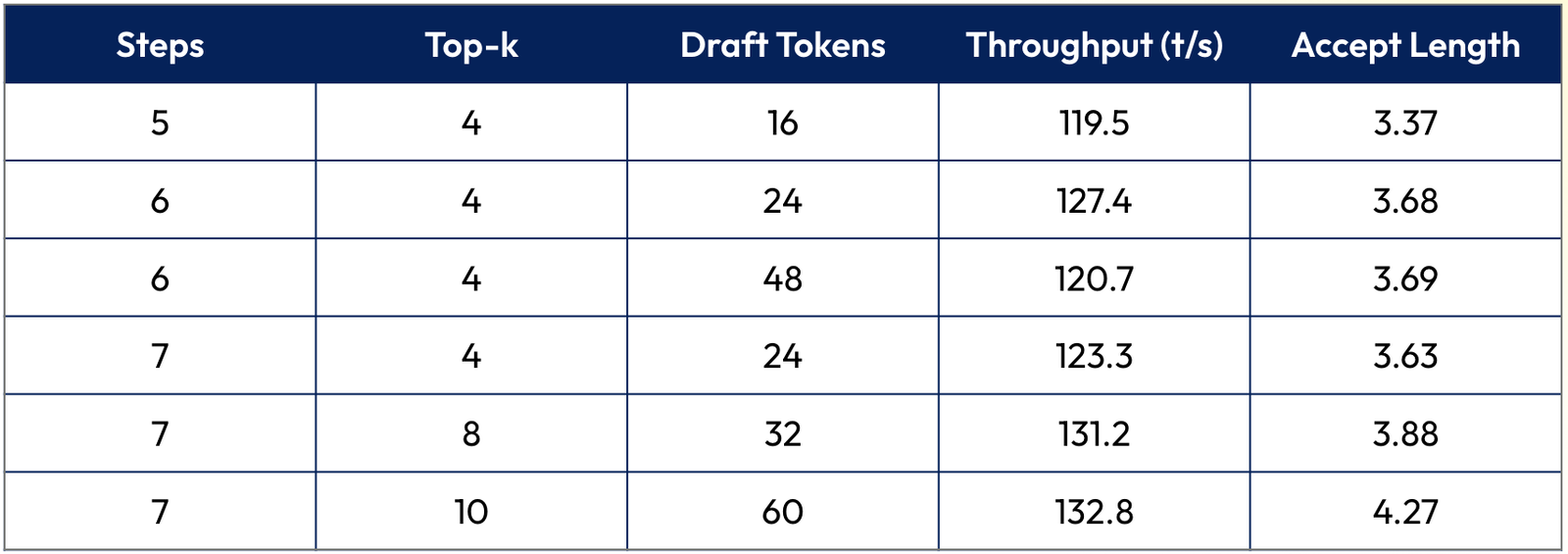
The pattern reveals that increasing depth (more speculative steps) helps more than increasing width (higher top-k). Going from 5 to 6 to 7 steps consistently improved throughput. Doubling num_draft_tokens at the same depth (6/4/24 vs 6/4/48) barely moved the needle.
Our interpretation: a well-trained EAGLE3 model naturally commits to a single high-confidence path through the tree. The branching helps, but is not the primary strategy. You're better off letting the model speculate further into the future than giving it more alternatives at each step.
There's an intriguing implication: we trained our model to speculate up to 7 tokens ahead. The throughput was still climbing at depth 7. Could we get more with depth 8, 9, 10? We don't know. We'd have to retrain. But the trend suggests there's still headroom!
The clipped wings
Not everything we tried worked. In the spirit of sharing the full picture, here’s what flopped:
- Quantizing the EAGLE model seemed like an obvious win: less data means faster inference, right? In practice, the EAGLE model is already tiny. The memory savings from quantization are negligible. Worse, you have to upcast back to bf16 for the actual matrix multiplications, so you're paying for a dequantize step with no meaningful throughput benefit. Native FP8 or FP4 training (not post-training quantization) might change this story, especially on Blackwell's hardware support for narrow formats. We haven't tested it yet.
- System prompt pinning: the idea of feeding the system prompt's hidden states into the EAGLE model to help it understand the "persona" it's drafting for is theoretically appealing. In practice, it would require slicing the intermediate state snapshots in a way that the current training pipeline doesn't support, and we suspect the improvement would be marginal. If someone wants to try this: good luck, and let us know how it goes.
- Multi-layer EAGLE heads: as mentioned, training with 2 or 3 layers in the draft model didn't improve accuracy, and SGLang won't load them anyway.
The eagle has landed
And finally, the moment of truth: how does our trained EAGLE3 model perform in the wild?
At low batch sizes (1~6 concurrent requests), EAGLE-3 on SGLang's default code path ("V1") delivers exactly what you'd hope: ~2x individual throughput, meaningful aggregate gains, no impact on time-to-first-token. In line with what the literature says.
At batch size 7 and above, EAGLE-3 on V1 starts losing to the baseline. The overhead of running the draft model, building the speculation tree, and verifying candidates starts eating into the gains. The crossover point was around 7 concurrent requests. Much earlier than we'd like.
SGLang's newer V2 speculative decoding backend (SGLANG_ENABLE_SPEC_V2=True) fixes this. With V2, EAGLE3 consistently outperforms the baseline at all batch sizes. The catch is that V2 currently forces topk=1, which means the tree degrades to a line, a chain. You lose the branching that EAGLE-3 was designed for. It's still faster, just... not as fast as it could be. The SGLang team is actively working on lifting this restriction.
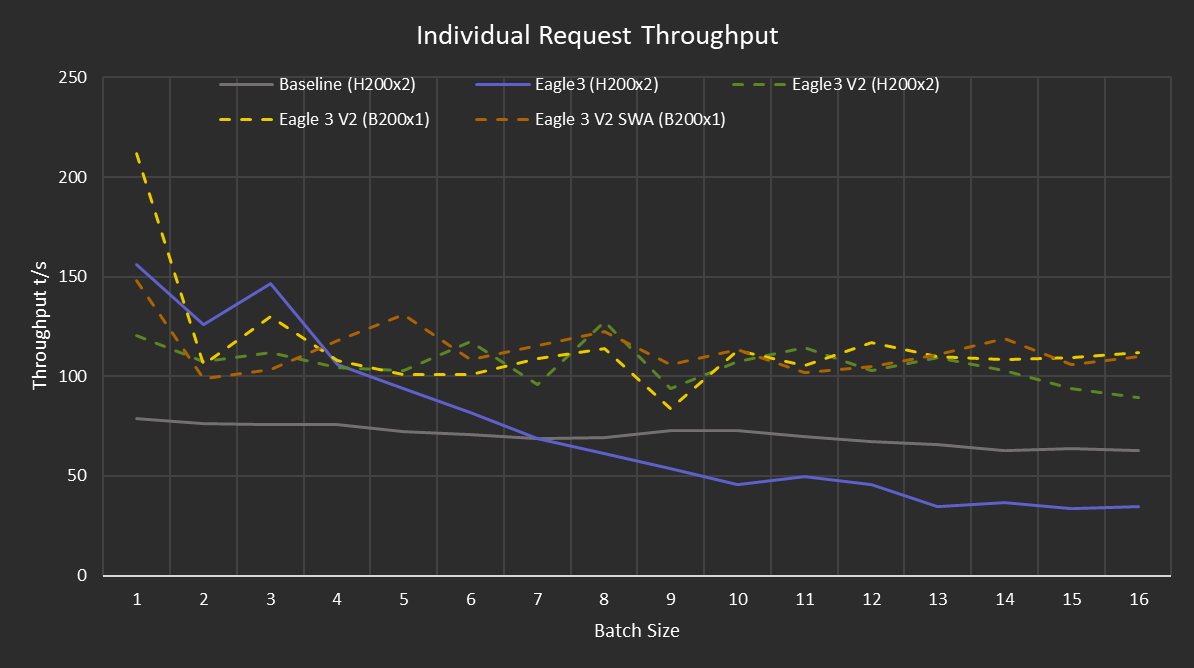
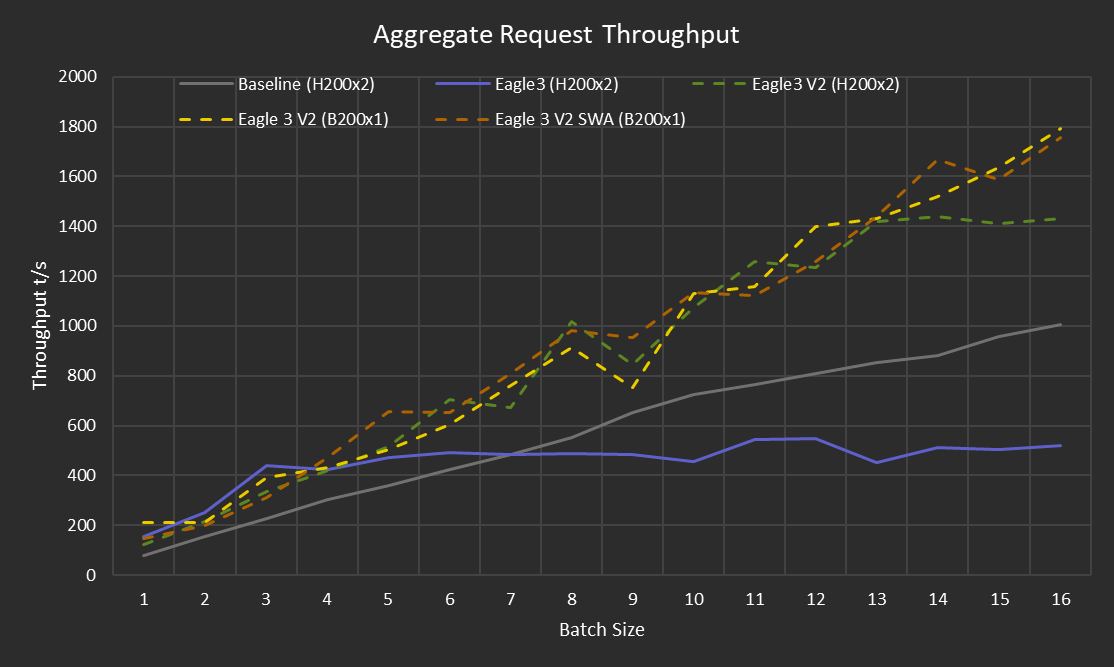
The biggest surprise was the hardware story. 1xB200 with EAGLE-3 outperformed 2xH200 without it. One GPU, almost half the cost, much better throughput.
We speculate (pun intended) this is because with a single GPU, the intermediate hidden states don't need to cross an interconnect to reach the EAGLE head: everything stays on-chip. Whether data-parallelizing the EAGLE model across a multi-GPU setup could close this gap is a research question for another day.
A nice catch
For OLMo-3.1-32B-Think on a single B200:
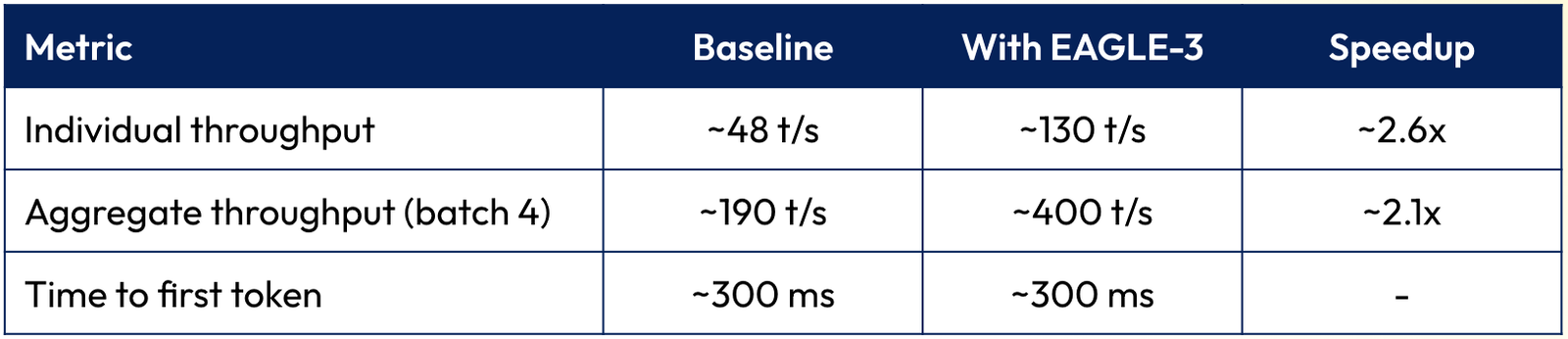
This is the same model. Same weights. Same outputs. Just faster: because a tiny auxiliary model is doing most of the token-by-token grunt work, and the real model only has to verify.
The training pipeline to get here involved regenerating a dataset, capturing 40 TiB of hidden states, running a hyperparameter sweep, benchmarking every checkpoint against real tasks, tuning inference parameters, and debugging a multi-stage pipeline across multiple GPU configurations. It's reproducible, but it's not a weekend project.
If you're running LLM inference at scale and this sounds like something you'd rather not build yourself, that's literally what Parasail does. We handle the infrastructure, the optimization, the eagle training - you get faster inference with the same API you're already using.
And if you do want to build it yourself: this post is your roadmap. Have fun!